|
|
|
|
|
|
|
|
|
|

The training of our model is divided into two stages. (Left) The LP-regressor processes the input facial image to generate LPMM parameters, and is trained so that the reconstructed facial landmark matches the original. (Right) The LP-adaptor is used to transform LPMM parameters into the latent space of a pretrained talking head model’s pose encoder. While training LP-adaptor, all weights other than LP-adaptor itself are frozen.

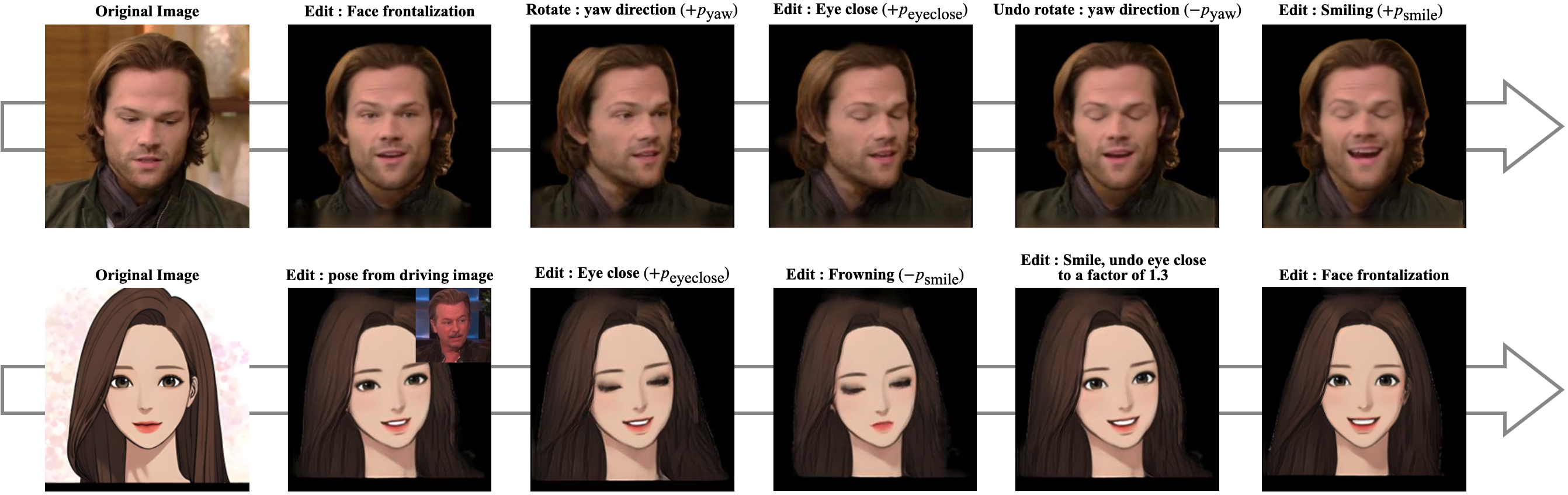
Rig-Lkie Control without Pose Source.

Rig-Lkie Control with Pose Source.
 |
Kwangho Lee, Patrick Kwon, Myung Ki Lee, Namhyuk Ahn, Junsoo Lee. LPMM: Intuitive Pose Control for Neural Talking-Head Model via Landmark-Parameter Morphable Model In CVPR Workshop 2023, AI4CC. [Paper] |
|
|